Behavioral Cloning and Painful Defeats at the Chess Club
The first algorithm people tried when building self-driving cars is behavioral cloning. Behavioral cloning is pretty simple in concept:
- Gather tons of human driving data, state action pairs:
(S_t, A_t) - Train a supervised model
f(S_t) -> A_t - Drive cars with that model. 1
This makes a lot of sense, but it doesn’t work. Supervised learning works for so many things like image classification, so why not for self-driving cars?
Supervised Learning: The Key Assumption
The key assumption in supervised learning is that the training data is sampled from the same population as test data. When this assumption is broken, supervised learning stops working. For example, say you train a model to classify images as either “animal” or “not an animal”, and you use a dataset of photos taken by wildlife photographers. Then, you give it a bunch of photos taken in metropolitan cities. The model is not going to do so well. This is why people working on image classification generally use really big datasets with images from a variety of sources.
Accumulated Error: Death Spiral Into the Deep, Dark Forest
Applying supervised learning to self-driving cars leads to this assumption being broken eventually. This is due to accumulated error. When the self-driving car begins its test run, it begins in the same state that the human-driven cars from its training data began. However, as it drives, it will inevitably make a tiny error. A human would easily correct this error, but for the self-driving car, this error puts the car in a state that is a tiny bit off from its training data. This causes it to make more errors, which puts the car in more unfamiliar states, which causes it to make more errors… and so forth. Now, the car is in a feedback loop that sends it veering off towards disaster.
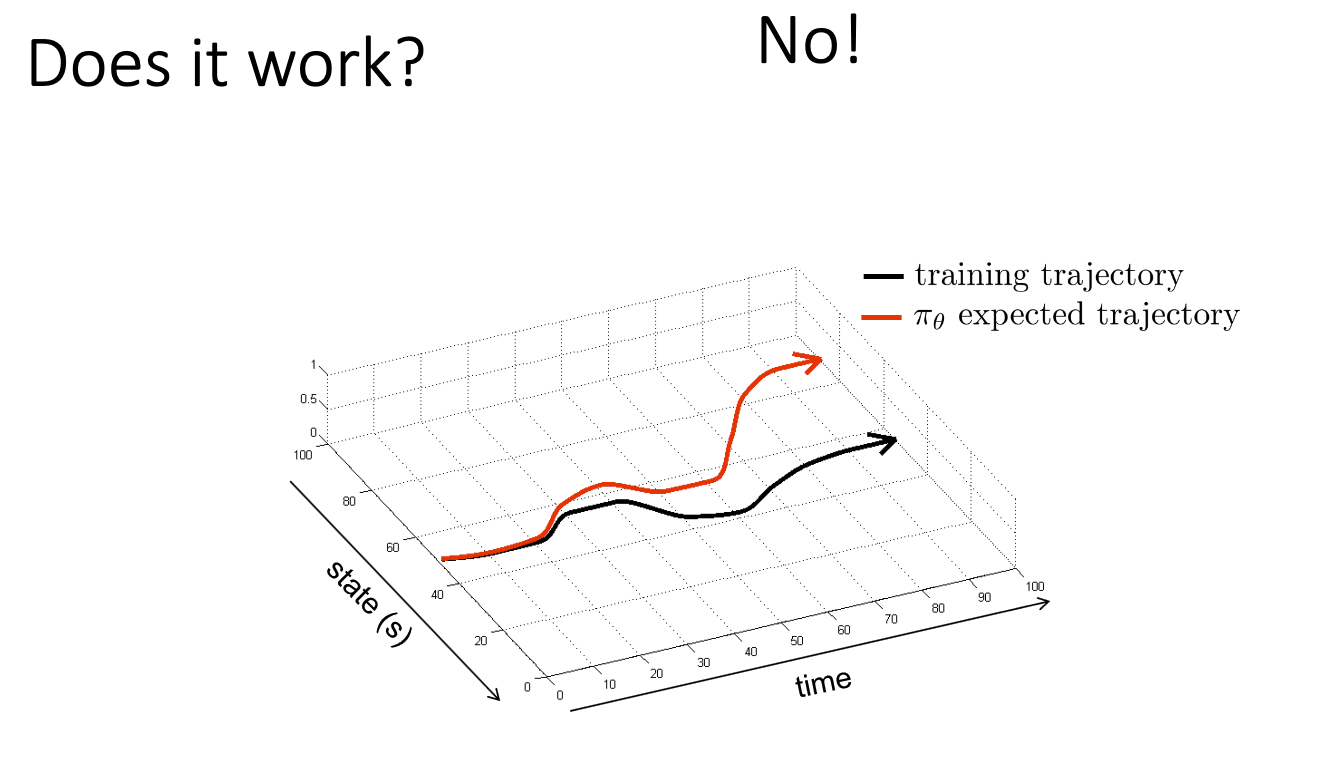 |
|---|
| Behavioral cloning death spiral. 2 |
Two Painful Defeats at the Chess Club
I promise this next part is related to behavioral cloning. Bear with me.
I’ve always spent way more time watching chess than I’ve spent playing chess. I watch youtube videos on chess strategy, openings, game analyses, etc. As of late, I’ve almost completely stopped playing chess online, and the only chess I play is a weekly classical rated game at the Seattle Chess Club.
I’m rated roughly 1400-1500. I played two games recently against the same opponent, rated roughly 2000-2100. One game, I had white, and one game I had black. I ran the games through a computer afterwards.
The Games
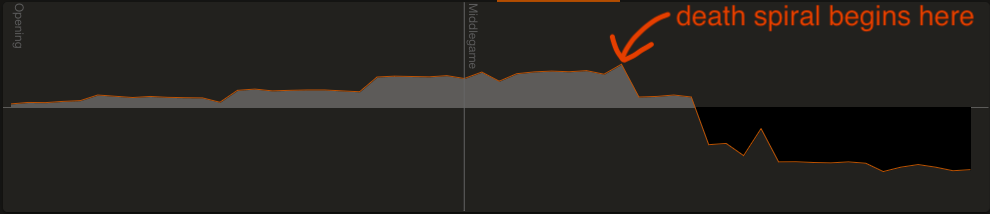 |
|---|
| First game where I was white. Y-axis is evaluation, x-axis is moves. |
The graph clearly shows that I was doing great through the opening and early middle game and built up a healthy advantage, and then my position crumbled.
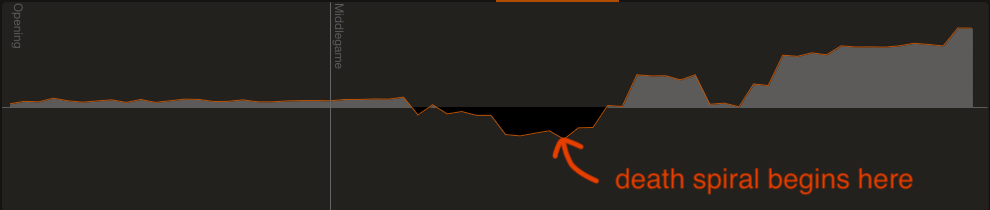 |
|---|
| Second game where I was black. Y-axis is evaluation, x-axis is moves. |
In this game, I am black, so the graph should be read “upside down”. This graph is a little trickier to interpret, but I think it tells the same story as the first one. The engine always prefers white in the opening, so that’s why the opening shows a small edge for white (my opponent). However, compared to the first graph, the edge for white is much smaller and does not increase, which I think means black (me) was doing well through the opening. Then, the game starts to favor black more and more until I eventually death spiral again.
I Need To Play More Chess.
How do I explain the difference in the quality of my play in the early and late stages of these games? Of course, there’s definitely more factors at play, but I think it’s interesting to compare myself to a behavioral learning algorithm. Early on, the game is more similar to chess that I’ve seen before (e.g. to what I’ve seen in videos), but over time, the game deviates to be less and less familiar, and thus the quality of my moves go down.
The interesting thing about chess is, my own accumulated error is not the sole source of deviation. My opponent decides the direction of the game as well.
Mikhail Tal, a former world champion, once said “You must take your opponent into a deep, dark forest where 2+2=5 and the path leading out is only wide enough for one.” In these games, I tried leading my opponent into a deep, dark forest, but it turned out that I wasn’t quite equipped to handle the forest myself.
Anyway, my conclusion from all of this is I need more “real” chess experience, not experience from watching others talk and think about chess. In behavioral cloning words, I need training data from states that I’m likely to enter, not just data from the IMs and GMs that I want to emulate who post videos online.
A big reason why I tended not to play a lot of chess was because I felt stressed out about losing rating points online. But ever since I’ve started playing over the board chess, I’ve started to care less and less about my online rating. So, my resolution is to play more chess online. This, too, is parallel to machine learing: when your models don’t work, collect more training data.